데이터 추가하기
데이터를 추가하기에 앞서, 우리가 데이터를 추가하기 위한 테이블은 employee이다. employee 테이블은 다음과 같이 구성되어 있다. 이제 이 employee 테이블에 데이터를 추가해 보자.

employee 테이블에 데이터를 추가하는 방법은 다음과 같다.
INSERT INTO employee VALUES(1, 'MESSI', '1987-02-01', 'M', 'DEV_BACK', 100000000, null)
INSERT INTO 뒤에 데이터를 추가하고자 하는 테이블을 추가하고, VALUES 키워드 뒤에는 추가하려 하는 값을 입력하면 된다.
VALUES에 해당하는 값들을 입력할 때 중요한 점은 값들의 순서이다. 즉, create table을 통해 employee 테이블을 정의할 때 사용했던 attribute들을 순서대로 입력해야 한다.
SQL이 정상적으로 실행되었다면, 다음과 같은 결과가 나온다.

이번에는 다음과 같은 INSERT 쿼리를 날려보도록 하자.
INSERT INTO employee VALUES(1, 'JANE', '1996-05-05', 'F', 'DSGN', 900000000, null)
‘JANE’이라는 이름을 가진 직원을 employee 테이블에 추가하였다. 하지만, 이 쿼리를 실행하면 성공적으로 성공적으로 쿼리가 실행될 것 같지만, 그렇지 않다.

다음과 같이 Duplicate entry ‘1’ for key ‘employee.PRIMARY’ 라는 에러 메시지가 뜨게 된다. 즉, 1이라는 값이 primary 키로 중복되기 때문에 에러가 발생한다.
이는 이전에 ‘MESSI’ 라는 이름을 가진 직원의 id를 1로 설정했기 때문에 primary key인 id가 중복되어 발생하는 문제이다.
이번에는 id 값을 2로 바꾸고 다음과 같은 SQL문을 실행해 보자. 이렇게 되면 primary key가 중복되지 않는다.
INSERT INTO employee VALUES(2, 'JANE', '1996-05-05', 'F', 'DSGN', 40000000, null)
하지만, 예상과는 다르게 이번에도 에러가 발생하게 된다.

Check constraint 'employee_chk_2' is violated. 가 발생한 이유는 처음에 employee 테이블을 정의했을 때, salary가 50000000 이상이어야 한다는 constraints를 걸어놨지만, 그 이하의 값을 입력했기 때문에 constraints을 위반하여 발생한 에러이다.

또한, 에러 메시지에서는 ‘employee_chk_2’라고 메시지가 떠 이것이 어떤 constraints를 위반했는지 정확히 알 수 없는 문제가 발생한다. 따라서 어떤 constraints 위반했는지 명확히 알기 위해서는 MySQL의 경우 SHOW CREATE TABLE "테이블명" 을 입력하면 된다.
SHOW CREATE TABLE employee
그러면 결과로 여러 메시지들이 뜨게 되고, 중간에 다음과 같은 결과가 나오게 된다. 이를 통해 ‘employee_chk_2’가 어떤 제약 조건을 위반하는지 알 수 있다.

이번에는 연봉까지 수정을 하여 다시 다음과 같은 INSERT 쿼리를 날려보도록 하자.
INSERT INTO employee VALUES(2, 'JANE', '1996-05-05', 'F', 'DSGN', 90000000, 111)
이 경우에도 여전히 에러 메시지가 발생한다. 에러 메시지를 살펴보면 중간에 foreign key constraint fails라는 문구가 있는 것이 보인다. 현재의 경우 111에 해당하는 부분이 foreign key를 나타낸다.
employee 테이블의 foreign key는 department 테이블을 참조하고 있는데, 현재 department 테이블에는 아무런 값도 존재하지 않기 때문에 에러가 발생하게 된다.

즉, foreign key constraint는 참조하는 값이 실제로 그 테이블에 있을 때에만 그 값을 지정해 줄 수 있다는 것을 의미한다.
다시 INSERT 쿼리를 수정하고, 다음과 같이 쿼리를 날려보면
INSERT INTO employee VALUES(2, 'JANE', '1996-05-05', 'F', 'DSGN', 90000000, null)
성공적으로 쿼리문이 실행된 것을 확인할 수 있다.
이번에는 ‘JENNY’에 대한 데이터를 employee 테이블에 다음과 같이 추가해 보자.
INSERT INTO employee (name, birth_date, sex, position, id)
VALUES ('JENNY', '2020-10-12', 'F', 'DEV_BACK', 3)
아까와 SQL문이 좀 달라진 것이 보일 것이다.
employee 테이블 뒤에 attribute의 이름들을 나열하는 부분이 추가되었다. 이 방법을 통해 값을 넣는 순서에 자유도가 생기고, 실제로 넣고 싶은 attribute에 대해서만 값을 넣을 수 있다.
여기까지 employee 테이블에 총 3명의 데이터를 추가해 보았다. 이제는 employee 테이블에 데이터 가 정확히 확인하기 위한 작업이 필요하다. 이를 위해 SELECT문을 활용할 수 있다.
SELECT * FROM employee
SELECT 뒤에 *를 붙이면, 전체 데이터를 확인할 수 있다. FROM 뒤에는 테이블명을 지정하면 된다.
SELECT문은 이번 파트에서는 맛보기로만 다루고, 다음 글에서 구체적으로 설명하도록 하겠다.
실행 결과를 확인하면, 다음과 같은 결과가 나오는데, 이를 통해 INSERT 문으로 삽입한 3개의 데이터가 입력한 대로 잘 들어간 것을 확인할 수 있다.
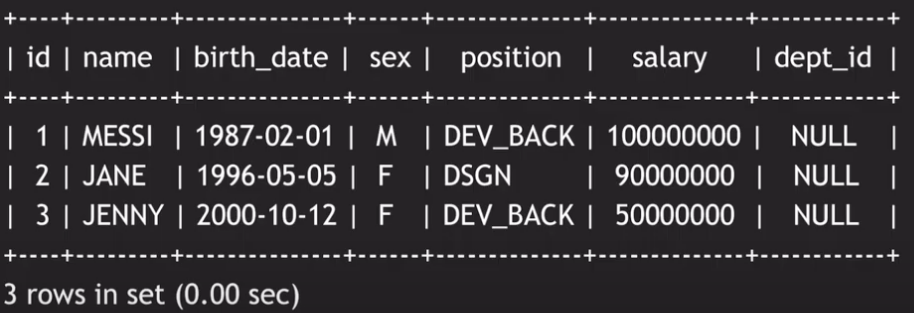
여기서 주목할 점은, ‘JENNY’의 경우 id, name, birth_date, sex, position에 대한 attribute를 지정해서 데이터를 삽입했기 때문에 salary, dept_id에 대한 값은 넣지 않았다. 하지만 ‘salary’의 경우 50000000으로 들어가 있는 것을 확인할 수 있다. 이는 처음 employee 테이블을 정의할 때 salary의 default를 50000000으로 설정했기 때문이다.
INSERT statement 정리
INSERT문은 크게 3가지 형태로 나뉜다.
데이터를 하나만 추가하는 경우
1. 모든 attribute에 대응하는 값을 넣어주고 싶은 경우
INSERT INTO table_name VALUES (comma-separated all values)
2. 내가 원하는 일부 attribute에 대해서만 내가 원하는 순서대로 값들을 넣고 싶을 때
INSERT INTO table_name(attributes list)
VALUES(attributes list 순서와 동일하게 comma-separated values);
한 번에 여러 개의 데이터를 추가하는 경우
3. VALUES 까지는 이전과 동일하며, 괄호로 여러 튜플들을 묶어 콤마로 구분 지어주면 된다.
INSERT INTO table_name VALUES (..., ..), (..., ..), (..., ..)
예를 들면, 다음과 같이 employee 테이블에 여러 개의 데이터를 추가하는 것이 가능하다.
INSERT INTO employee VALUES
(4, 'BROWN', '1996-03-13', 'M', 'CEO', 120000000, null),
(5, 'DINGYO', '1990-11-05', 'M', 'CTO', 120000000, null),
(6, 'JULIA', '1986-12-11', 'F', 'CFO', 120000000, null);
나머지 테이블에도 다음과 같이 데이터들을 추가하도록 하자. 테이블 구조는 이전 글을 참고하면 된다.
2024.02.23 - [Database] - [데이터베이스] SQL 개념, 데이터베이스 정의 방법
department 테이블

project 테이블

works_on 테이블

데이터 수정하기
이번에는 데이터를 수정하는 방법에 대해 알아보자. 그전에, SELECT 문을 이용해 employee 테이블을 조회하는 쿼리를 날려보면
SELECT * FROM employee
다음과 같은 결과가 나온다. employee 테이블의 dept_id를 보면, 처음 INSERT 문으로 employee 테이블에 데이터를 추가할 당시에는 department 테이블에 아무런 값도 없었기 때문에 NULL로 처리하였다. 하지만, 이제는 department 테이블에 데이터가 있으므로, employee 테이블의 dept_id를 수정해야 한다.
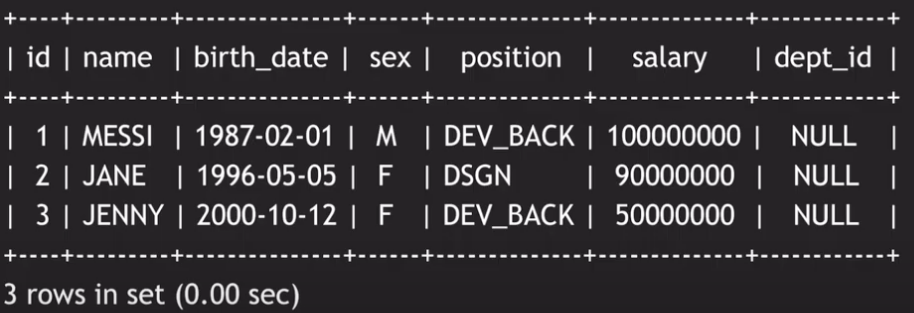
먼저, employee 테이블에서 Messi에 대한 정보를 수정해 보자. 다음과 같은 UPDATE statement를 바탕으로 Messi의 정보를 수정할 것이다.
예제 1
- employee ID가 1인 Messi는 개발(department) 팀 소속이다.
- 개발팀 ID는 1003이다
- Messi의 소속팀 정보를 업데이트해주자.
그러면, 다음과 같이 UPDATE 문을 작성할 수 있다.
UPDATE employee SET dept_id = 1003 WHERE id=1
UPDATE 키워드 뒤에 업데이트하고자 하는 테이블명을 적고, SET 이라는 키워드를 적은 뒤 바꾸려는 속성 값을 입력한다.
우리의 목적은 dept_id를 1003으로 바꾸는 것이다. 또한, 우리는 id가 1인 Messi의 dept_id를 변경해야 하기 때문에 WHERE문에 ‘id=1’ 조건을 명시하였다.
쿼리를 실행하면, 다음과 같이 정상적으로 처리되는 걸 확인할 수 있다.

실제로 SELECT를 통해 확인을 해보면
SELECT * FROM employee WHERE id = 1
Messi의 dept_id가 null에서 1003으로 업데이트된 것을 확인할 수 있다.

Messi를 제외한 나머지 두 명의 임직원에 대해서도 dept_id를 업데이트하는 쿼리를 다음과 같이 날릴 수 있다.
UPDATE employee SET dept_id = 1004 WHERE id = 2
UPDATE employee SET dept_id = 1003 WHERE id = 3
예제 2
- 개발팀 연봉을 모두 두 배로 인상하고 싶다
- 개발팀 ID는 1003이다
이 경우에는 다음과 같이 쿼리를 날릴 수 있다.
UPDATE employee SET salary*2 WHERE dept_id=1003
예제 3
- 프로젝트 ID 2003에 참여한 임직원의 연봉을 두 배로 인상하고 싶다.
먼저, 연봉 정보는 employee 테이블에 존재하기 때문에 employee 테이블이 필요하다. 또한, id가 2003인 프로젝트에 참가한 임직원을 알아야 하기 때문에 works_on 테이블이 추가로 필요하다.
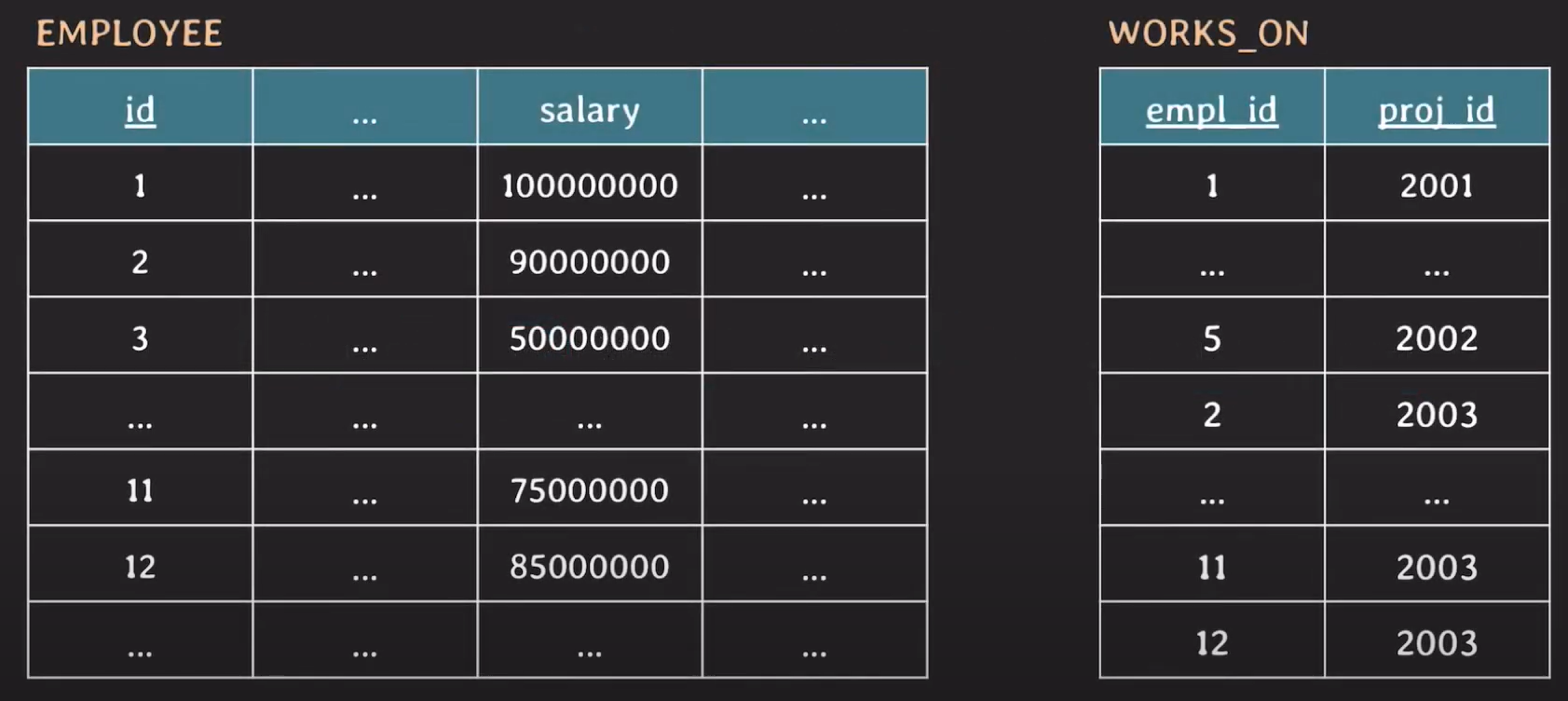
따라서 다음과 같이 쿼리를 날리면 된다.
UPDATE employee, works_on
SET salary = salary * 2
WHERE id = empl_id and proj_id = 2003
여기서 주목해야 할 점은 WHERE id = empl_id 부분이다. 이 조건을 통해서 두 개의 테이블을 연결할 수 있는 것이다. 하지만, id, empl_id의 경우 두 attribute가 어떤 테이블에 존재하는지 알기가 어렵다. 따라서 이를 직관적으로 표현하기 위해 다음과 같이 SQL 문을 변경할 수 있다.
UPDATE employee, works_on
SET salary = salary * 2
WHERE employee.id=works_on.empl_id and proj_id = 2003
employee.id=works_on.empl_id 와 같이 테이블 명 뒤에 dot(.)을 찍고, 그 뒤에 attribute 이름을 적어주면 좀 더 직관적으로 표현이 가능하다.
예제 4
- 회사의 모든 구성원의 연봉을 두 배로 올리고 싶다.
UPDATE employee
SET salary = salary * 2
이전 예제와의 가장 큰 차이는 WHERE 절이 없다는 것이다. 즉, WHERE 절을 입력하지 않으면, 해당 테이블에서 업데이트하려는 attribute가 모두 업데이트 되게 된다.
UPDATE statement 정리
UPDATE를 정리하면 다음과 같이 표현할 수 있다.
UPDATE table_name(s)
SET attribute = value [, attribute = value, .. ]
[WHERE condition(s)]
UPDATE 뒤에는 테이블 이름을 적어주면 되며, 하나 이상의 테이블을 적을 수 있다. 그다음에 SET이라는 키워드를 적어주고, UPDATE 해줄 attribute이름과 value를 적어주면 된다. 또한, 두 개 이상의 attribute를 UPDATE 해줄 수도 있다. 마지막으로 필요하다면, WHERE 절을 적어 UPDATE 해주고 싶은 튜플들이 만족해야 하는 조건을 하나 이상 적어주면 된다.
데이터 삭제하기
이번에는 데이터를 삭제하는 방법에 대해 알아보도록 하자. 이번에도 예제를 통해 알아보도록 하자.
예제 1
- John이 퇴사를 하게 되면서 employee 테이블에서 John 정보를 삭제해야 한다.
- John의 employee ID는 8이다.
- 현재 John은 project 2001에 참여하고 있었다.
먼저, employee 테이블에서 John의 정보를 삭제해야 하기 때문에 employee 테이블이 필요하고, John의 project id가 2001이므로, 이 정보를 담은 works_on 테이블 또한 삭제가 필요하다.

다음과 같이 SQL문을 작성하면 어떻게 될까?
DELETE FROM employee WHERE id = 8
이 경우, employee 테이블만 지정했기 때문에 works_on 테이블의 정보도 추가로 삭제해야 한다는 생각이 들 것이다. 하지만, 그럴 필요가 없다. 왜냐하면, works_on 테이블을 생성할 때 employee 테이블을 참조하는 empl_id를 foreign key로 지정해 주면서 on delete CASECADE 옵션을 주었기 때문이다. 따라서 empl_id가 참조하고 있는 테이블의 id가 삭제될 경우 empl_id에 대응하는 튜플도 함께 삭제된다.

예제 2
- Jane이 휴직을 떠나게 되면서 현재 진행 중인 프로젝트에서 중도하차하게 됐다
- Jane의 ID는 2다
DELETE FROM works_on WHERE empl_id = 2
예제 3
- 현재 Dingyo가 두 개의 프로젝트에 참여하고 있었는데 프로젝트 2001에 선택과 집중을 하기로 하고 프로젝트 2002에서는 빠지기로 했다.
- Dingyo의 ID는 5다
DELETE FROM works_on WHERE empl_id = 5 and proj_id = 2002
만약, Dingyo가 참여하고 있는 프로젝트가 2001, 2002뿐만 아니라 더 많은 개수의 프로젝트에 참여할 경우 2002만 지정하면 2002에 해당하는 프로젝트만 삭제되는 문제가 발생한다.
이 경우 다음과 같이 SQL문을 변경해 2001을 제외한 나머지 프로젝트들을 삭제할 수 있다.
DELETE FROM works_on WHERE empl_id = 5 and proj_id <> 2001
즉 <> 는 제외한다는 의미이며, != 와 동일한 의미로 사용된다.
예제 4
- 회사에 큰 문제가 생겨서 진행 중인 모든 프로젝트들이 중단됐다
DELETE FROM project
WHERE절이 없을 경우 모든 데이터를 삭제하게 된다.
DELETE statement 정리
DELETE FROM table_name
[WHERE condition(s)]
DELETE의 경우 DELETE FROM 키워드 뒤에 테이블 이름을 붙여주고, 삭제하고자 하는 조건을 WHERE 절에 입력하면 된다.
'Database' 카테고리의 다른 글
| [데이터베이스] SQL 개념, 데이터베이스 정의 방법 (0) | 2024.02.23 |
|---|---|
| [데이터베이스] 관계형 데이터베이스 개념과 relation, primary key, foreign key, constraints (0) | 2024.02.21 |
| [데이터베이스] 데이터베이스(database) 기본 개념 (1) | 2023.11.18 |
| [데이터베이스] 데이터베이스 종류 및 간단 설명 (0) | 2023.11.08 |