관계형 데이터베이스 개념
데이터베이스에서 relation이란, 수학에서 나온 개념을 의미한다. 따라서, 수학에서 의미하는 relation에 대해 먼저 알아보도록 하자.
수학에서의 relation
set(집합)
- 서로 다른 elements를 가지는 collection으로 중복되지 않는다.
- 하나의 set에서 elements의 순서는 중요하지 않다.
cartesian product
- 집합을 이용해 만들 수 있는 모든 쌍
수학에서의 relation
- cartesian product의 부분집합
- tuple들의 set(집합)
relational data model에서 relation
relational data model
- set은 domain을 의미한다.
- domain은 값들의 집합이다.
- domain마다 이름을 붙일 수 있다.
- tuple들을 가질 수 있다.
- relational data model 전체를 relation이라 부른다.
student relation을 통한 relational data model 이해
먼저 student relation에서 domain을 정의하면, 다음과 같다.
- students_ids: 학번 집합, 7자리 integer 정수
- human_names: 사람 이름 집합, 문자열
- university_grades: 대학교 학년 집합, {1,2,3,4}
- major_names: 대학교에서 배우는 전공 이름 집합
- phone_numbers: 핸드폰 번호 집합
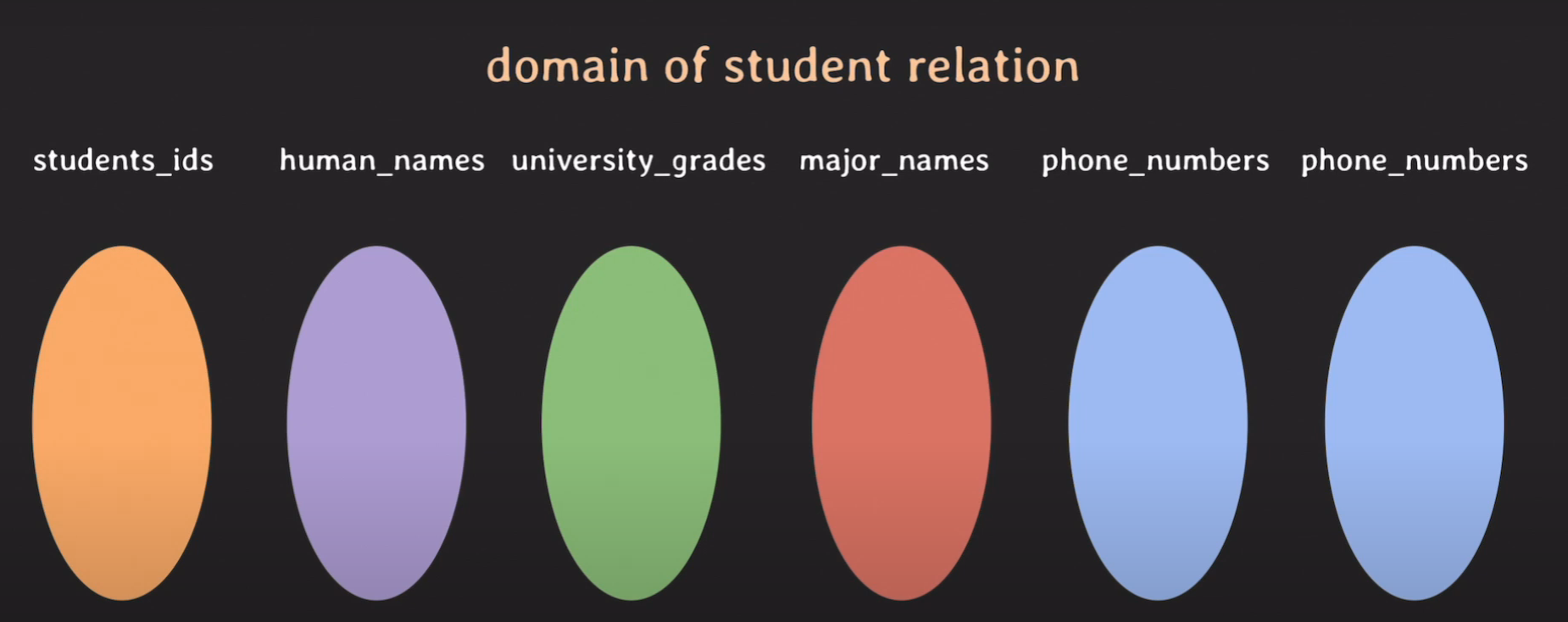
다음과 같이 학생 릴레이션에 대한 도메인이 있고, 여기서 phone_number가 두 번 나타나게 된다. 이는 student relation을 data model을 통해 나타내려 하다 보니, 학생의 비상 연락망도 있어야 된다는 생각이 들었기 때문이다.
따라서, phone_numbers는 다음과 같이 두 가지 용도로 사용될 수 있다.
- 학생의 전화번호를 저장하기 위해 사용
- 그 학생의 비상 연락망(가족, 친구 등)을 저장하기 위해 사용
동일한 도메인이 같은 릴레이션에서 두 번 사용되는데 그 역할이 다르다는 것을 알 수 있다. 따라서 각각의 도메인들이 릴레이션에서 어떠한 역할을 수행하는지 수행하는 역할의 이름을 붙여줘야 하며, 이를 attribute라고 부른다.
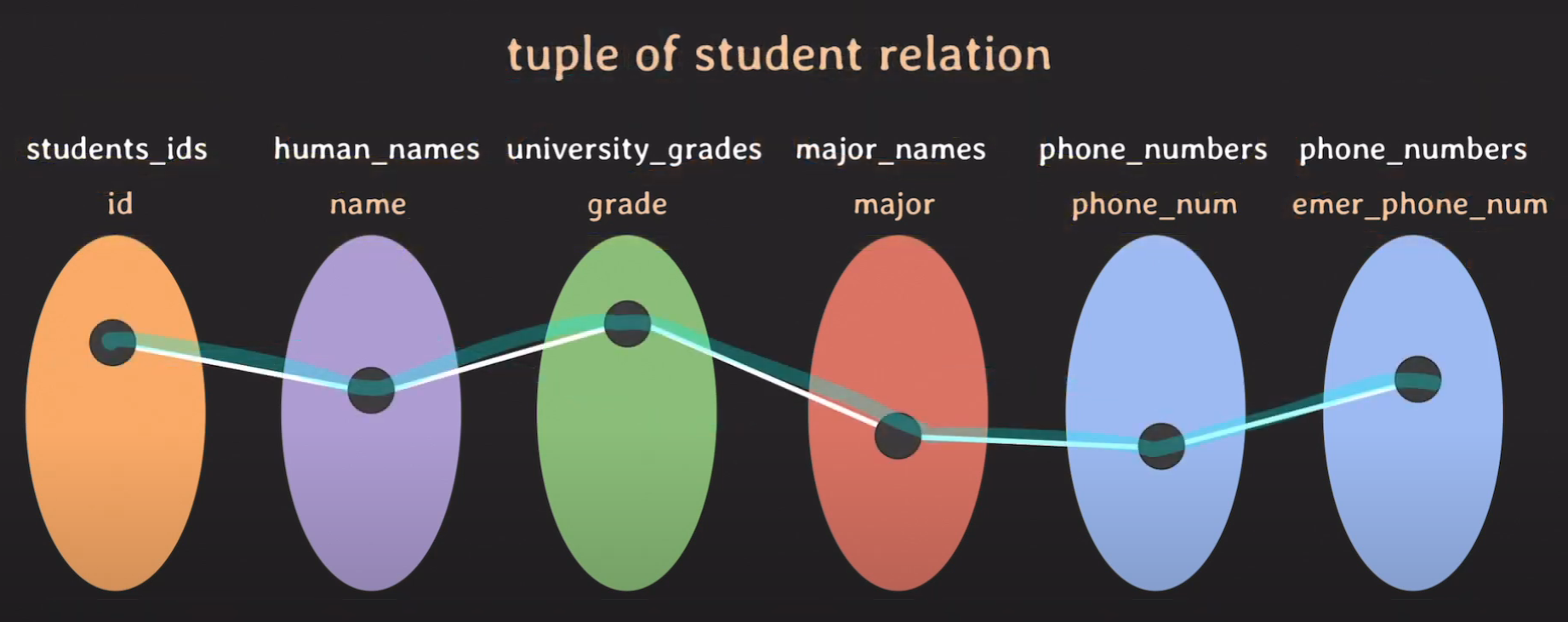
각각의 도메인에 attribute를 붙여 준 모습은 다음과 같다.

- id: students relation에서 학생의 id를 나타낸다.
- name: 학생의 이름을 나타낸다.
- grade: 학생의 학년을 나타낸다.
- major: 학생의 전공을 나타낸다.
- phone_num: 학생의 전화번호를 나타낸다.
- emer_phone_num: 학생의 비상 연락처를 나타낸다.
student relation에서는 tuple이 다음과 같이 표시된다.
하지만, relational data model을 사용할 때는 위의 그림과 같이 사용하지 않고, 테이블을 통해 표현한다.
따라서 relational data model에서 relation을 테이블이라고 많이 사용한다.
student relational data model을 테이블을 통해 표현하면 다음과 같다.

방금까지 배웠던 개념을 적용해 보면, 다음과 같이 나타낼 수 있다.
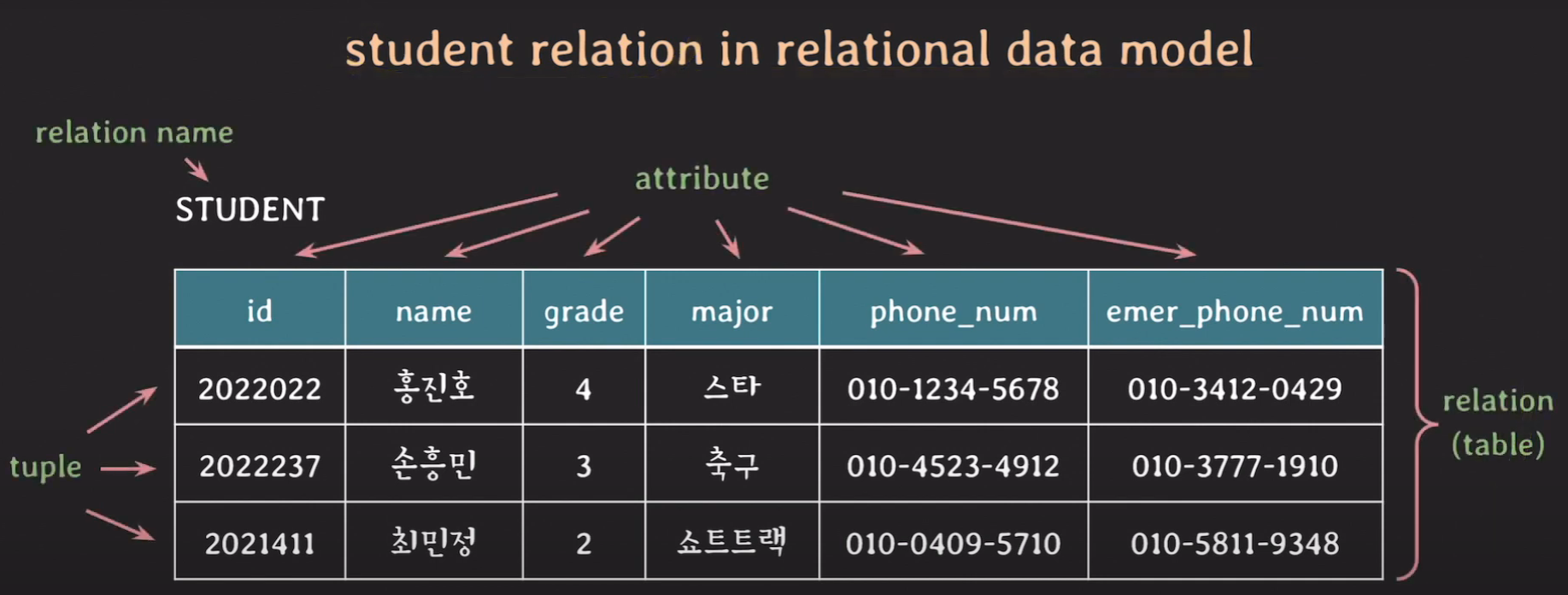
- attribute: 각 도메인에서 릴레이션 안에서 부여된 역할 이름
- tuple: attribute 하나하나의 값들로 이루어진 리스트
- relation(table): 전체
- relation name: relation(table) 이름
정리
| 주요 개념 | 설명 |
| domain | 더 이상 나누어질 수 없는 값들의 집합 |
| domain_name | domain 이름 |
| attribute | domain이 relation에서 맡은 역할의 이름 |
| tuple | 각 attribute의 값으로 이루어진 리스트, 일부 값은 NULL일 수 있음. |
| relation | tuple들의 집합 |
| relation_name | relation의 이름 |
relation schema, degree, relation state
relation schema
- relation의 구조를 나타낸다.
- relation 이름과 attributes 리스트로 표기된다.
- ex) STUDENT(id, name, grade, major, phone_num, emer_phone_num)
- attributes와 관련된 constraints도 포함한다.
degree of relation(릴레이션의 차수)
- relation schema에서 attributes의 수
- ex) STUDENT(id, name, grade, major, phone_num, emer_phone_num)의 degree는 6이다.
relation (or relation state)
- relation은 relation state라는 의미로도 사용된다.
- 이는 임의의 시점에서의 tuple의 집합을 말한다.
relational database
- relational database는 relational data model에 기반하여 구조화된 database를 말한다.
- relational database는 여러 개의 relations로 구성된다.
relational database schema
- relation schemas set + integrity constraints set
relation의 특징
- relation은 중복된 tuple을 가질 수 없다. (중복을 허용하지 않는다)

- relation의 tuple을 식별하기 위해 attribute의 부분 집합을 key로 설정한다.

다음과 같이 id를 통해 각 tuple을 unique 하게 구분하여 식별할 수 있다.
- relation에서 tuple들의 순서는 중요하지 않다.
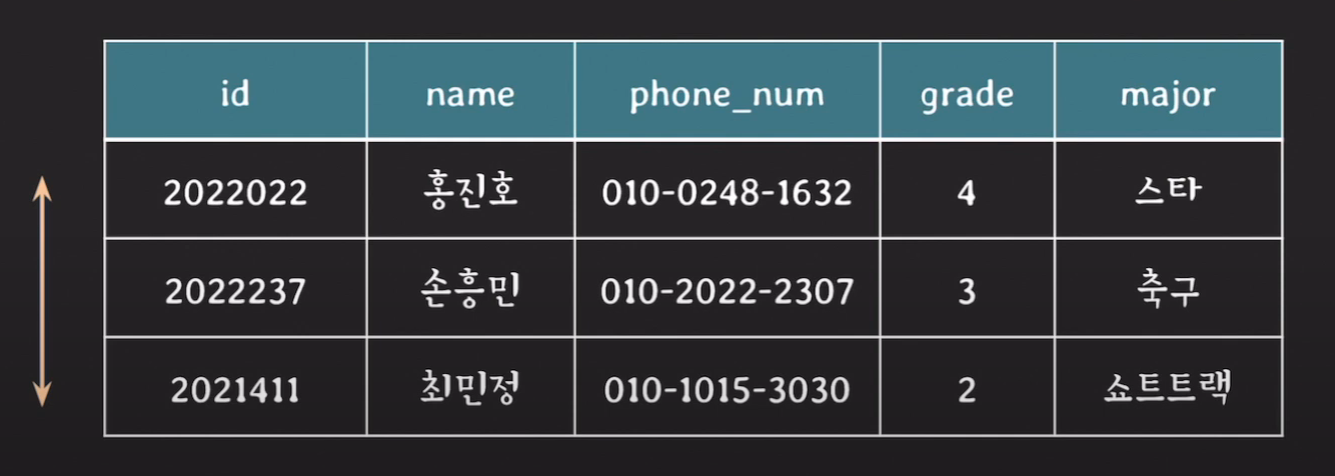
해당 tuple들의 순서가 바뀌어도 relation의 의미가 달라지지 않는다. 따라서 순서를 정하는 방법이 여러 가지가 있을 수 있다.
- 하나의 relation에서 attribute의 이름은 중복되면 안 된다.

- 하나의 tuple에서 attribute의 순서는 중요하지 않다.

attribute 순서를 바꿔도 그 의미가 달라지지 않는다.
- attribute는 더 이상 나누어질 수 없는 값이어야 한다.

다음처럼 address attribute에서 서울특별시 강남구 청담동은 서울특별시, 강남구, 청담동으로 나눌 수 있고, major attribute에서 컴공, 디자인도 컴공과 디자인으로 나누어야 한다.
NULL의 의미
- 값이 존재하지 않는다.
- 값이 존재하나, 아직 그 값이 무엇인지 알지 못한다.
- 해당 사항과 관련이 없다.
NULL은 중의적인 의미를 가지기 때문에 최대한 쓰지 않는 것이 좋다.
keys
super key
- relation에서 tuples를 unique 하게 식별할 수 있는 attributes set
candidate key
- 어느 한 attribute라도 제거하면 unique 하게 tuples를 식별할 수 없는 super key
- key 또는 minimal superkey라고 부른다.
primary key
- relation에서 tuple을 unique 하게 식별하기 위해 선택된 candidate key
- 보통 primary key를 고를 때는 attribute 숫자가 적은 것을 선택한다.
- primary key로 선택될 경우 밑에 언더바를 사용한다.
unique key
- primary key가 아닌 candidate keys
- alternate key라고도 부른다.
foreign key
- 다른 relation의 PK를 참조하는 attributes set
constraints
constraints란, relational database의 relations들이 언제나 항상 지켜줘야 하는 제약 사항을 말한다.
데이터의 일관성을 보장하기 위해 사용되는 개념이다.
implicit constraints
- relational data model 자체가 가지는 constraints
- relation은 중복되는 tuple을 가질 수 없다.
- relation 내에서는 같은 이름의 attribute를 가질 수 없다.
schema-based constraints
- 주로 DDL을 통해 schema에 직접 명시할 수 있는 constraints
- explicit constraints라고 부른다.
종류
domain constraints
- attribute의 value는 해당 attribute의 domain에 속한 value여야 한다.
- 다음과 같이 grade는 1,2,3,4 학년을 표현하는 attribute이기 때문에 100은 들어갈 수 없다.

key constraints
- 서로 다른 tuples는 같은 value의 key를 가질 수 없다.
- 다음처럼 서로 다른 tuple은 key 값인 id가 달라야 한다.

Null value constraint
- attribute가 NOT NULL로 명시됐다면 NULL을 값으로 가질 수 없다.

entity integrity constraint
- primary key는 value에 NULL을 가질 수 없다.
referential integrity constraint
- FK와 PK의 도메인이 같아야 하고, PK에 없는 values를 FK가 값으로 가질 수 없다.
참고
https://www.youtube.com/watch?v=gjcbqZjlXjM&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=2
'Database' 카테고리의 다른 글
| [데이터베이스] SQL로 DB에 데이터를 추가, 수정, 삭제하기 (2) | 2024.02.29 |
|---|---|
| [데이터베이스] SQL 개념, 데이터베이스 정의 방법 (0) | 2024.02.23 |
| [데이터베이스] 데이터베이스(database) 기본 개념 (1) | 2023.11.18 |
| [데이터베이스] 데이터베이스 종류 및 간단 설명 (0) | 2023.11.08 |