연봉 예측 분석
회귀 분석
연봉 예측 분석을 시작하기 전에 회귀 분석이 무엇인지에 대해 알아보자.
아래의 그래프에서 빨간 점들은 실제 데이터를 나타낸다. 실제 데이터와 거리가 최소가 되는 방정식인 Y = wX + b를 찾아내는 과정을 회귀 분석이라고 한다.

즉, 회귀분석은 방적식의 계수인 w와 b를 잘 찾아내는 것이다. 그럼 이를 데이터 분석에 어떻게 적용할 수 있을까?

이 표를 보면 나이와 몸무게를 방정식의 X1, X2로 나타낼 수 있고, 키를 방정식의 Y로 정의할 수 있다. 즉, Y = w1X1 + w2X2 + b로 나타낼 수 있다.
회귀 분석은 해당 방정식에서 1, 2, 3번 데이터로 w1, w2, b라는 세 개의 계수를 추정하고, 마지막 4번 데이터를 가지고 계수가 잘 추정이 됐는지 테스트한다. 이후 실제 키와 비교를 통해 추정한 키와 실제 키가 비슷하면 회귀 분석이 잘 된 것으로, 비슷하지 않다면 회귀 분석이 잘 되지 않은 것으로 판단한다.
여기서 1, 2, 3번 데이터를 학습 데이터 셋, 4번 데이터를 테스트 데이터라고 부른다.
프로야구 연봉 데이터 분석
기본적인 개념에 대해 알아보았으니, 본격적으로 연봉 데이터를 예측 분석해 보자. 분석할 데이터로 2017, 2018년의 국내 프로야구 연봉 데이터를 사용하였다. 데이터는 투수와 타자와 관련된 데이터 두 가지로 나뉜다.
Step1. 탐색 : 프로야구 연봉 데이터 살펴보기
필요 라이브러리 import
실습을 진행하기 전에, 필요 라이브러리를 import 한다.
# -*- coding: utf-8 -*-
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
프로야구 연봉 데이터셋 읽어오기
pandas의 read_csv를 이용하여 투수와 타자에 대한 연봉 데이터를 읽어온다.
picher_file_path = 'data/picher_stats_2017.csv'
batter_file_path = 'data/batter_stats_2017.csv'
picher = pd.read_csv(picher_file_path)
batter = pd.read_csv(batter_file_path)
프로야구 연봉 데이터셋의 기본 정보
투수 데이터를 이용해 실습을 진행할 것이다. 추후 타자 데이터에 대한 실습도 진행하려 한다.
picher.columns
picher 데이터프레임의 column 정보를 확인한 결과는 다음과 같다.

head()를 통해 picher 데이터프레임을 미리 보기 한 결과는 다음과 같다.
picher.head()

shape를 통해 pitcher의 열과 행이 어떤 구조로 이루어져 있는지 확인할 수 있다.
picher.shape
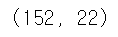
picher 데이터 프레임은 152개의 행과 22개의 열로 구성된다.
예측할 대상인 연봉에 대한 정보를 describe()를 통해 확인한다.
picher['연봉(2018)'].describe()

2018년 연봉 분포를 히스토그램으로 출력한다.
picher['연봉(2018)'].hist(bins=100)
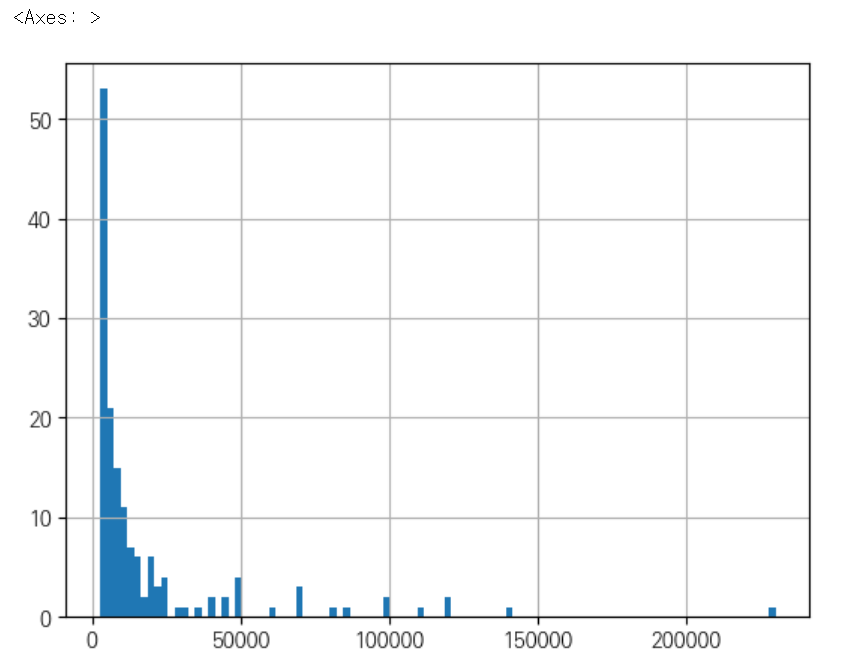
연봉이 5억 단위로 나누어져 있는데, 연봉이 5억 정도가 되는 선수가 많지 않은 걸 확인할 수 있다.
다음으로 2018년 연봉의 boxplot을 출력한다.
# 연봉의 boxplot을 출력한다.
picher.boxplot(column=['연봉(2018)'])

해당 그림에서 점으로 표현된 데이터는 일반적인 범주를 조금 벗어나는 데이터를 의미한다. 따라서, 고액 연봉자들이 많지 않다는 것을 확인할 수 있다.
회귀분석에 사용할 피처 살펴보기
먼저, 회귀분석에 사용할 피처 정보가 담긴 picher_features_df를 새로 생성한다.
picher_features_df = picher[['승', '패', '세', '홀드', '블론', '경기', '선발', '이닝', '삼진/9',
'볼넷/9', '홈런/9', 'BABIP', 'LOB%', 'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR',
'연봉(2018)', '연봉(2017)']]
피처 각각에 대한 히스토그램을 출력하는 함수를 정의한다.
# 피처 각각에 대한 히스토그램 출력
def plot_hist_each_column(df):
plt.rcParams['figure.figsize'] = [20, 16]
fig = plt.figure(1)
# df의 column 갯수 만큼의 subplot을 출력한다.
for i in range(len(df.columns)):
ax = fig.add_subplot(5, 5, i+1)
plt.hist(df[df.columns[i]], bins=50)
ax.set_title(df.columns[i])
plt.show()이 함수는 데이터 프레임을 넣으면 각 column을 전체 그래프의 subplot으로 추가하여 5x5 형태의 그래프로 하나씩 출력하는 함수이다.
실제 함수 호출을 통해 결과를 확인해 보자.
plot_hist_each_column(picher_features_df)
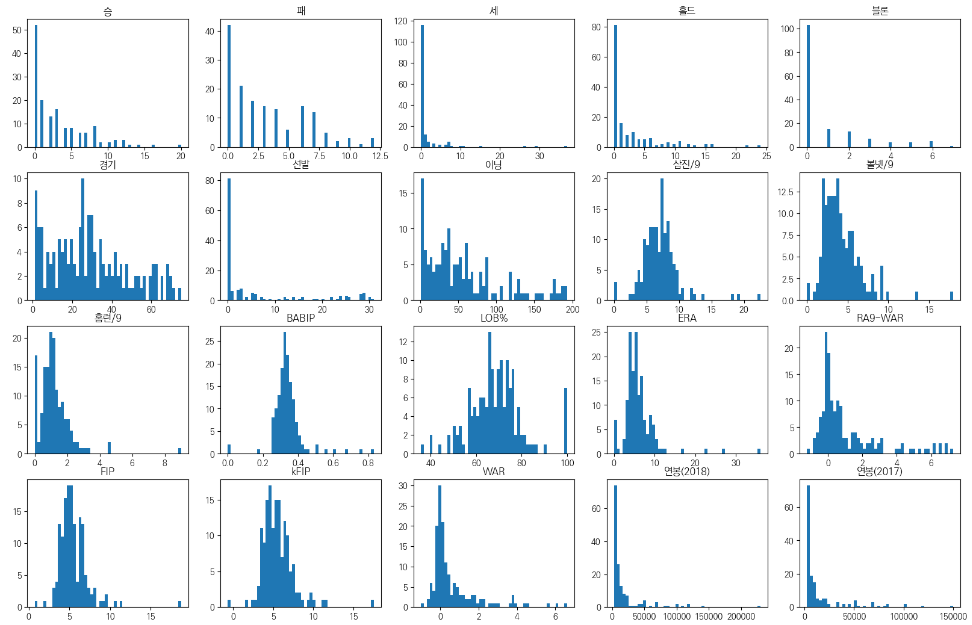
이를 통해 각 피처들의 분포를 확인할 수 있다.
Step2. 예측 : 투수의 연봉 예측하기
피처들의 단위 맞추기 : 피처 스케일링
위의 피처들의 히스토그램을 확인해 보면, 단위가 모두 제각각인 것을 확인할 수 있다. 우리는 투수의 연봉을 예측하기 위해 피처들의 단위를 맞춰주어야 한다.
왜냐하면 우리는 회귀 분석에서 방정식을 만들어야 하는데, 만약 방정식이 y = 10X1 * 0.1X2 라면 X1과 X2가 y에 기여하는 부분이 달라지게 된다. 즉, picher의 단위 차이가 많이 나게 되면, 회귀 분석의 영향력을 제대로 분석할 수 없기 때문에 피처들의 단위를 맞춰주어야 한다. 이를 '피처 스케일링'이라고 부른다.
# pandas 형태로 정의된 데이터를 출력할 때, float 모양으로 출력되게 해준다.
pd.options.mode.chained_assignment = None
# 피처 각각에 대한 scailing을 수행하는 함수를 정의한다.
def standard_scailing(df, scale_columns):
for col in scale_columns:
series_mean = df[col].mean()
series_std = df[col].std()
df[col] = df[col].apply(lambda x: (x-series_mean)/series_std)
return df피처 스케일링을 위해 피처 각각에 대한 스케일링을 수행하는 함수를 정의해 주었다. 데이터 프레임과 column에 대한 리스트가 인자로 들어오게 되고, 각 column의 평균과 표준편차를 구해 각 column마다 (x-평균) / 표준편차 식을 이용해 z를 구하여 데이터 프레임을 업데이트해 준다.
피처 각각에 대한 피처 스케일링을 수행한다.
scale_columns = ['승', '패', '세', '홀드', '블론', '경기', '선발', '이닝', '삼진/9',
'볼넷/9', '홈런/9', 'BABIP', 'LOB%', 'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR', '연봉(2017)']
picher_df = standard_scailing(picher, scale_columns)
변경된 결과를 head를 통해 확인한다.
picher_df = picher_df.rename(columns={'연봉(2018)':'y'})
picher_df.head()


데이터들의 범위가 비슷해진 것을 확인할 수 있는데, 여기서 중요한 점은 y는 바꾸지 않았다는 것이다. 즉, x들만 바꾸어주었다.
피처들의 단위 맞추기 : one-hot-encoding
만약 "딸기", "키위", "멜론"... 과 같은 과일 데이터가 있다고 가정하자. 컴퓨터는 0과 1로 이루어진 2진수를 사용하기 때문에 사람이 이해할 수 있는 텍스트 정보는 방정식으로 만들 수 없다. 즉, 이러한 데이터들을 방정식으로 만들어 주기 위해 벡터화하는 과정을 one-hot-encoding 방법이라 한다.
즉, "딸기", "키위", "멜론" 피처가 있을 때 딸기는 [1 0 0], 키위는 [0 1 0] 멜론은 [0 0 1]으로 표현하는 방법을 말한다.
현재 데이터에서는 팀명이 '한화', '삼성' 등의 문자열 데이터를 갖기 때문에 팀명에 one-hot-encoding을 적용해주어야 한다.
# 팀명 피처를 one-hot-encoding으로 변경
team_encoding = pd.get_dummies(picher_df['팀명'])
picher_df = picher_df.drop('팀명', axis=1)
picher_df = picher_df.join(team_encoding)one-hot-encoding을 적용해 줄 때는 pandas의 get_dummies를 사용하면 된다. one-hot-encoding을 적용해 준 다음, 기존에 있던 '팀명' 데이터를 삭제하고, one-hot-encoding을 적용한 데이터를 새로 추가해 준다.
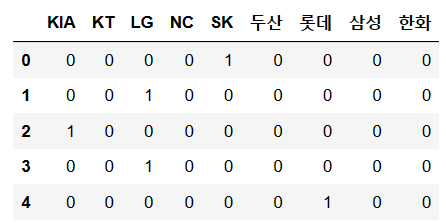
미리 보기를 통해 확인한 team_encoding의 내용은 다음과 같다.
team_encoding.head()
one-hot-encoding을 적용하여 수정된 picher_df의 내용은 다음과 같다.
picher_df.head()

회귀 분석 적용하기
회귀 분석을 위한 준비가 끝났으니, 회귀 분석을 적용해 보자.
회귀 분석을 위한 학습, 테스트 데이터셋 분리
from sklearn import linear_model
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from math import sqrt
# 학습 데이터와 테스트 데이터 분리
X = picher_df[picher_df.columns.difference(['선수명', 'y'])]
y = picher_df['y']
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2, random_state=19)
필요 라이브러리들을 import 한 다음, X로 '선수명', 'y' 피처를 제외한 모든 피처를 사용하고, y로는 y(2018 연봉) 피처를 사용한다. train_test_split 함수를 통해 80%를 학습 데이터로 사용하고, 20%를 테스트 데이터로 사용한다.
회귀 분석 계수 학습 & 학습된 계수 출력
먼저, sklearn 라이브러리에 있는 LinearRegression(선형 회귀 모델)을 학습할 수 있도록 모델 object lr을 생성하고, fit 함수를 통해 학습 데이터를 이용해 모델을 학습시킨다.
# 회귀 분석 계수 학습
lr = linear_model.LinearRegression()
model = lr.fit(X_train, Y_train)
학습이 완료되면, 학습된 계수를 출력한다.
# 학습된 계수 출력
print(lr.coef_)

Step3. 평가 : 예측 모델 평가하기
어떤 피처가 가장 영향력이 강한 피처일까
statemodels의 OLS를 이용해 모델을 학습하면, 모델의 summary를 얻어낼 수 있다.
import statsmodels.api as sm
# statsmodel 라이브러리로 회귀 분석을 수행합니다.
X_train = sm.add_constant(X_train)
model = sm.OLS(y_train, X_train).fit()
model.summary()
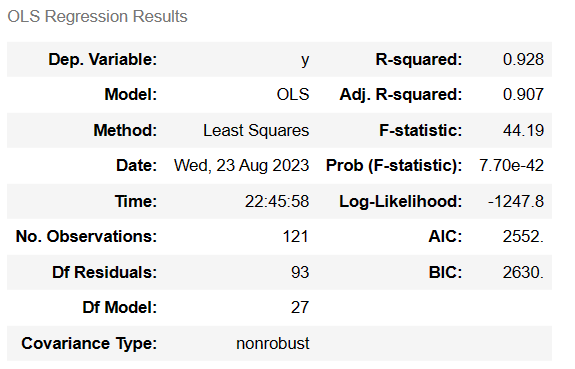
- R-squared: 그래프의 직선이 데이터를 얼마나 잘 설명하는지 나타낸다.
- F-statistic: 모델 자체가 얼마나 잘 수행됐는지 나타내는 검증 지표이다.
- Prob (F-statistic): 값이 작을수록 믿을만한 회귀 분석임을 의미한다.
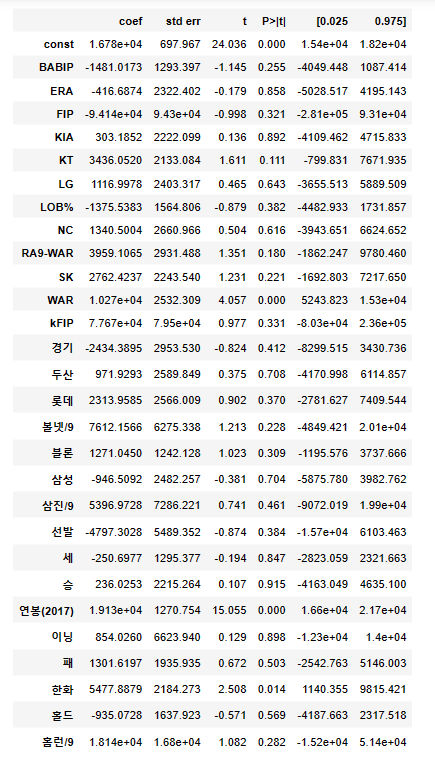
- t : 각 피처에 대한 t 통계량
- P > ltl : t에 대한 p value
p value가 0에 가까울수록 유효한 검증임을 의미한다. 따라서 모델의 유의미한 피처에는 WAR, 연봉(2017), 한화가 있다는 것을 알 수 있다.
학습된 계수를 그래프로 그려서 어떤 피처가 영향력이 강한 피처인지를 확인할 수도 있다.
# 한글 출력을 위한 사전 설정
mpl.rc('font', family='KoPubDotum Light')
plt.rcParams['figure.figsize'] = [20, 16]
# 회귀 계수를 리스트로 반환
coefs = model.params.tolist()
coefs_series = pd.Series(coefs)
# 변수명을 리스트로 반환
x_labels = model.params.index.tolist()
# 회귀 계수를 출력
ax = coefs_series.plot(kind='bar')
ax.set_title('feature_coef_graph')
ax.set_xlabel('x_features')
ax.set_ylabel('coef')
ax.set_xticklabels(x_labels)
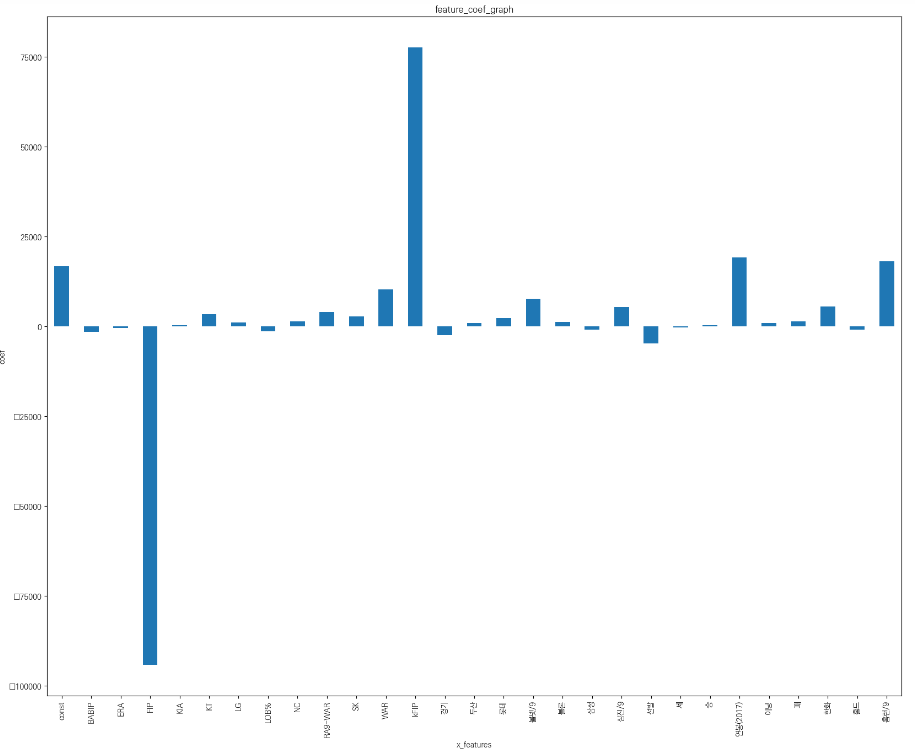
그래프를 통해 FIP, KFIP, 연봉(2017), 홈런 등이 영향력이 높은 피처임을 알 수 있다.
예측 모델의 평가
먼저, R2 score을 통해 학습 데이터와 테스트 데이터를 넣어 모델을 평가할 수 있다.
# 회귀 분석 모델을 평가
print(model.score(X_train, y_train)) # train R2 score를 출력
print(model.score(X_test, y_test)) # test R2 score를 출력
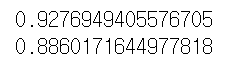
두 번째로 RMSE score을 통해 모델을 평가할 수 있다.
# 회귀 분석 모델을 평가
y_predictions = lr.predict(X_train)
print(sqrt(mean_squared_error(y_train, y_predictions))) # train RMSE score를 출력
y_predictions = lr.predict(X_test)
print(sqrt(mean_squared_error(y_test, y_predictions))) # test RMSE score를 출력

RMSE score는 그래프에서 실제 데이터와 그려진 직선까지의 거리들을 모두 합한 값에 루트를 씌운 값을 나타낸다.
피처들의 상관관계 분석
import seaborn as sns
# 피처들의 상관관계 행렬을 계산한다.
corr = picher_df[scale_columns].corr(method='pearson')
show_cols = ['win', 'lose', 'save', 'hold', 'blon', 'match', 'start',
'inning', 'strike3', 'ball4', 'homerun', 'BABIP', 'LOB',
'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR', '2017']
# corr 행렬 히트맵을 시각화
plt.rc('font', family='KoPubDotum Light')
sns.set(font_scale=1.5)
hm = sns.heatmap(corr.values,
cbar = True,
annot = True,
square = True,
fmt = '.2f',
annot_kws={'size':15},
yticklabels=show_cols,
xticklabels=show_cols)
plt.tight_layout()
plt.show()

피처들의 상관관계 행렬을 계산하여 seaborn 라이브러리를 통해 heatmap을 그려 상관관계를 그래프로 확인할 수 있다. 가운데 대각선에 있는 값들은 모두 1이 되어야 하며, 대각선에 있는 값이 아닌데 1에 가깝거나 1인 값들은 서로 상관관계가 높다는 것을 알 수 있다.
회귀 분석의 예측 성능을 높이기 위한 방법 : 다중공산성 확인
다중공산성이란, 변수 간의 상관관계가 높아서 분석에 부정적인 영향을 미치는 상황을 말한다. 여러 피처 간의 연관성을 고려하였을 때, VIP 계수가 10 정도를 넘어가면 문제가 있는 피처라고 볼 수 있다.
파이썬에서는 variance_inflation_factor를 import 하여 공산성을 검증할 수 있다.
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif['VIF Factor'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif['features'] = X.columns
vif.round(1)

실행 결과를 통해 FIP와 홈런 피처가 공산성이 높은 것을 알 수 있다.
적절한 피처로 다시 학습하기
여태까지 유의미한 피처와 영향력이 있는 피처에 대해 확인해 보았으니, 피처를 재선정하여 다시 모델을 학습해 보도록 하자.
# 피처를 재선정한다.
X = picher_df[['FIP', 'WAR', '볼넷/9','삼진/9', '연봉(2017)']]
y = picher_df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# 모델을 학습한다.
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)
모델의 학습 결과를 출력하여 확인한다.
# 결과를 출력한다.
print(model.score(X_train, y_train)) # train R2 score를 출력
print(model.score(X_test, y_test)) # test R2 score를 출력
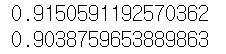
불필요한 피처를 제거했을 때 훨씬 결과가 좋아진 모습을 확인할 수 있다.
다시 VIF 계수를 출력하여 다중공산성을 확인해 보면
# 피처마다의 VIF 계수를 출력한다.
X = picher_df[['FIP', 'WAR', '볼넷/9', '삼진/9', '연봉(2017)']]
vif = pd.DataFrame()
vif['VIF Factor'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif['features'] = X.columns
vif.round(1)

10을 넘은 vif 계수가 하나도 없는 것을 확인할 수 있다. 즉, 적절한 피처의 선택을 통해 다중공산성의 문제가 사라지고, 예측 모델의 정확도도 더 올라가는 결과를 가져왔다.
Step4. 시각화 : 분석 결과의 시각화
마지막으로, 시각화를 통해 분석 결과를 확인해 보도록 하자.
예상 연봉과 실제 연봉 비교
2018년 연봉을 실제로 잘 예측해 내는지 실제 연봉과 비교를 해보기 위해 예측된 2018년 연봉을 데이터 프레임에 추가한다.
X = picher_df[['FIP', 'WAR', '볼넷/9', '삼진/9', '연봉(2017)']]
predict_2018_salary = lr.predict(X)
picher_df['예측연봉(2018)'] = pd.Series(predict_2018_salary)
예상 연봉과 실제 연봉을 비교할 수 있는 데이터 프레임을 생성하여, 가장 연봉이 높은 선수부터 내림차순으로 출력한다.
# 원래의 데이터 프레임을 다시 로드한다.
picher = pd.read_csv('data/picher_stats_2017.csv')
picher = picher[['선수명', '연봉(2017)']]
# 원래의 데이터 프레임에 2018년 연봉 정보를 합친다.
result_df = picher_df.sort_values(by=['y'], ascending=False)
result_df.drop(['연봉(2017)'], axis=1, inplace=True, errors='ignore')
result_df = result_df.merge(picher, on=['선수명'], how='left')
result_df = result_df[['선수명', 'y', '예측연봉(2018)', '연봉(2017)']]
result_df.columns = ['선수명', '실제연봉(2018)', '예측연봉(2018)', '작년연봉(2017)']
# 재계약하여 연봉이 변화한 선수만을 대상으로 관찰합니다.
result_df = result_df[result_df['작년연봉(2017)'] != result_df['실제연봉(2018)']]
result_df = result_df.reset_index()
result_df = result_df.iloc[:10, :]
result_df.head(10)

마지막으로 시각화를 통해 예측 연봉과 실제 연봉을 좀 더 쉽게 비교하여 확인할 수 있다.
# 선수별 연봉 정보(작년 연봉, 예측 연봉, 실제 연봉)를 bar 그래프로 출력한다.
mpl.rc('font', family='KoPubDotum Light')
result_df.plot(x='선수명', y=['작년연봉(2017)', '예측연봉(2018)', '실제연봉(2018)'], kind="bar")

'Programming > Python' 카테고리의 다른 글
| [파이썬] 데이터 분석 - 2.1 pandas 기초 익히기 (0) | 2023.08.16 |
|---|---|
| [파이썬] 데이터 분석 - 1. 아나콘다(Anaconda) 설치와 주피터 노트북(Juptyer Notebook) 실행 (0) | 2023.08.16 |
| [파이썬] 문법 정리 - 리스트 자료형 (0) | 2023.07.11 |
| [파이썬] 문법 정리 - 수 자료형 (0) | 2023.06.25 |